In der heutigen technologiegetriebenen Welt sind die Begriffe "Künstliche Intelligenz", "Machine Learning" und "Deep Learning" allgegenwärtig. du versprechen, Branchen zu revolutionieren, Prozesse zu optimieren und unser tägliches Leben zu verändern. Doch während diese Begriffe oft synonym verwendet werden, verbergen sich dahinter unterschiedliche Konzepte mit spezifischen Fähigkeiten und Anwendungsbereichen. Insbesondere die Abgrenzung zwischen Machine Learning (ML) und Deep Learning (DL) ist für viele Unternehmer und Entscheider unklar. Das Verständnis dieser Unterschiede ist jedoch entscheidend, um das volle Potenzial dieser Technologien für das eigene Unternehmen zu erschließen.
Dieser Artikel dient als dein umfassender Leitfaden, um die Mysterien hinter Machine Learning und Deep Learning zu lüften. Wir werden die grundlegenden Konzepte einfach und verständlich erklären, die wichtigsten Unterschiede herausarbeiten und dir anhand von praxisnahen Beispielen zeigen, wie diese Technologien bereits heute erfolgreich eingesetzt werden. Ziel ist es, dir das nötige Wissen an die Hand zu geben, um fundierte Entscheidungen darüber zu treffen, wie KI-Lösungen wie die von [Prozessmeister](/termin) dein Unternehmen voranbringen können.
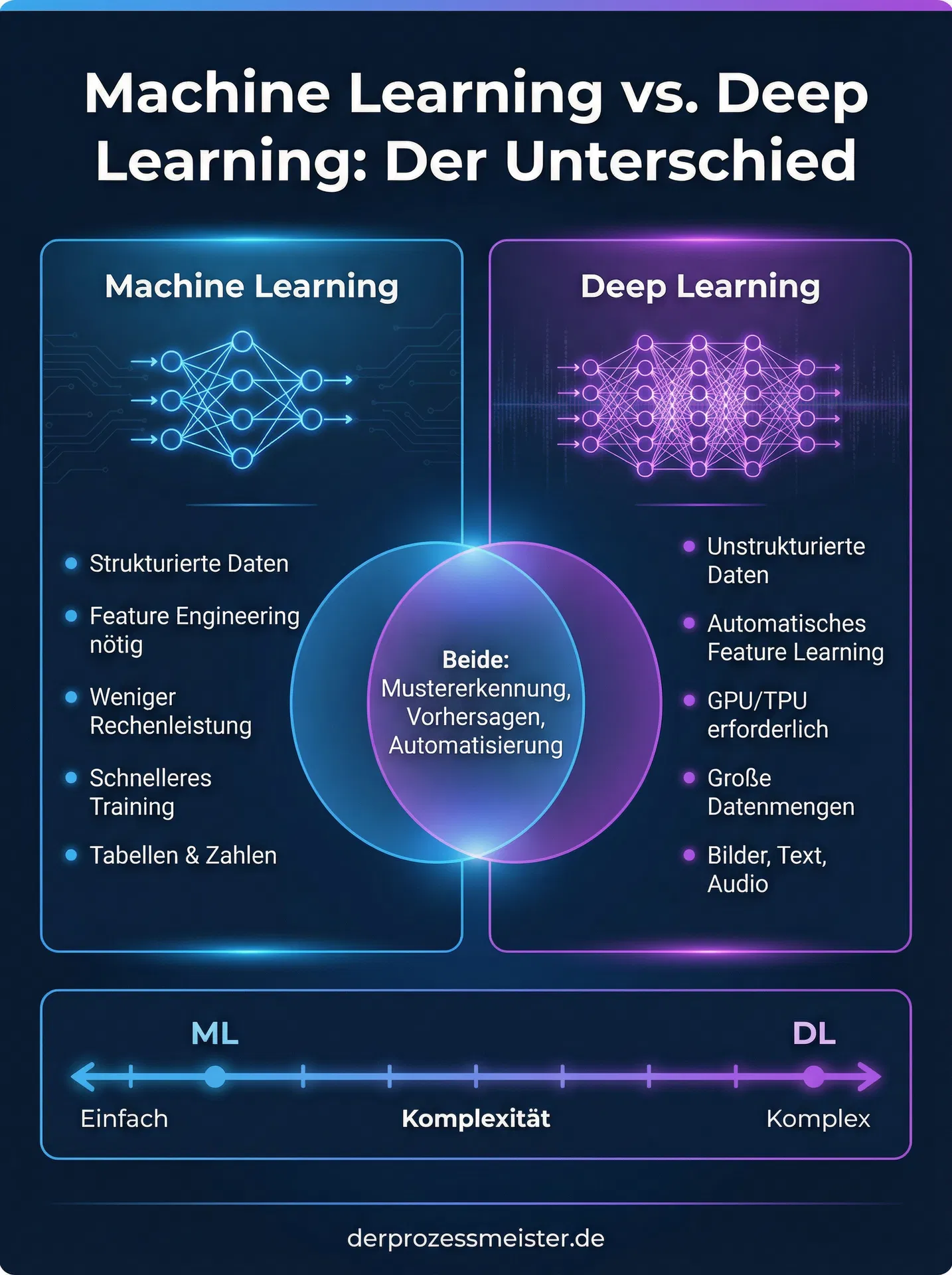
Was ist Machine Learning (ML)? - Eine Grundlage
Machine Learning, zu Deutsch maschinelles Lernen, ist ein Teilbereich der künstlichen Intelligenz (KI). Die Kernidee besteht darin, Computern die Fähigkeit zu verleihen, aus Daten zu lernen und Muster zu erkennen, ohne dass sie für jede spezifische Aufgabe explizit programmiert werden müssen. Stell es dir wie einen digitalen Auszubildenden vor, der durch Erfahrung immer besser wird. Anstatt ihm jeden einzelnen Schritt vorzugeben, füttere ihn mit einer großen Menge an Daten und lassen ihn selbstständig Zusammenhänge und Regeln ableiten.
Dieser Lernprozess wird durch Algorithmen ermöglicht, die in der Lage sind, Daten zu analysieren, daraus zu lernen und auf dieser Basis Vorhersagen oder Entscheidungen zu treffen. Ein klassisches Beispiel ist der Spam-Filter in deinem E-Mail-Postfach. Anstatt Tausende von Regeln manuell zu definieren, was eine Spam-E-Mail ausmacht, wird ein ML-Modell mit unzähligen Beispielen von Spam- und Nicht-Spam-Mails trainiert. Das Modell lernt so, charakteristische Merkmale von Spam zu identifizieren und neue, unbekannte E-Mails entsprechend zu klassifizieren.
Die drei Hauptarten des Machine Learning
- **Überwachtes Lernen (Supervised Learning):** Dies ist die am weitesten verbreitete Methode. Hierbei werden dem Algorithmus "gelabelte" Daten zur Verfügung gestellt. Das bedeutet, jeder Datensatz im Trainingsmaterial ist bereits mit dem korrekten Ergebnis oder der richtigen Kategorie versehen. Das Spam-Filter-Beispiel fällt in diese Kategorie. Weitere Anwendungsfälle sind die Vorhersage von Immobilienpreisen basierend auf Merkmalen wie Größe und Lage oder die Erkennung von handschriftlichen Zahlen.
- **Unüberwachtes Lernen (Unsupervised Learning):** Im Gegensatz zum überwachten Lernen arbeitet diese Methode mit ungelabelten Daten. Der Algorithmus versucht, eigenständig verborgene Strukturen, Muster oder Cluster in den Daten zu finden. Ein typisches Anwendungsfeld ist die Kundensegmentierung, bei der Kunden anhand ihres Kaufverhaltens in verschiedene Gruppen eingeteilt werden, ohne dass diese Gruppen vorher definiert sind. Dies hilft Unternehmen, ihre Marketingstrategien gezielter auszurichten.
- **Bestärkendes Lernen (Reinforcement Learning):** Diese Methode ist von der Verhaltenspsychologie inspiriert. Ein "Agent" lernt durch Interaktion mit seiner Umgebung, indem er für gewünschte Aktionen belohnt und für unerwünschte bestraft wird. Das Ziel des Agenten ist es, seine Belohnungen im Laufe der Zeit zu maximieren. Bestärkendes Lernen ist die treibende Kraft hinter selbstfahrenden Autos, die lernen, Verkehrsregeln einzuhalten, oder hinter KI-Systemen, die komplexe Spiele wie Schach oder Go auf übermenschlichem Niveau meistern.
Was ist Deep Learning (DL)? - Die nächste Evolutionsstufe
Deep Learning ist kein eigenständiges Feld, sondern eine spezialisierte und weiterentwickelte Form des Machine Learning. Man kann es als die nächste Evolutionsstufe betrachten. Der entscheidende Unterschied und die namensgebende Eigenschaft ist die Verwendung von künstlichen neuronalen Netzen mit vielen Schichten (daher "deep", also "tief"). Diese tiefen Architekturen ermöglichen es den Modellen, weitaus komplexere Muster und Hierarchien in den Daten zu erkennen, als es mit traditionellen ML-Methoden möglich wäre.
Die Inspiration für Deep Learning stammt direkt aus der Funktionsweise des menschlichen Gehirns. Unser Gehirn verarbeitet Informationen in einem Netzwerk von Neuronen, die in verschiedenen Schichten angeordnet sind. Jede Schicht ist für die Erkennung bestimmter Merkmale zuständig, von einfachen Kanten und Formen bis hin zu komplexen Objekten wie Gesichtern. Deep-Learning-Modelle imitieren diese Struktur. Eine erste Schicht könnte in einem Bild vielleicht Kanten erkennen, die nächste Schicht kombiniert diese Kanten zu einfachen Formen wie Augen oder Nasen, und eine weitere Schicht setzt diese Formen zu einem vollständigen Gesicht zusammen.
Dieser hierarchische Lernprozess, auch als "Feature-Extraktion" bekannt, ist der größte Vorteil von Deep Learning. Bei traditionellen ML-Verfahren müssen Experten oft manuell die relevanten Merkmale aus den Rohdaten extrahieren und aufbereiten – ein Prozess, der als "Feature Engineering" bekannt ist und sehr zeitaufwendig sein kann. Deep-Learning-Algorithmen hingegen lernen diese Merkmale weitgehend automatisch aus den Daten. Das macht sie extrem leistungsfähig bei der Verarbeitung von unstrukturierten Daten wie Bildern, Texten und Sprache, bei denen die relevanten Merkmale nicht offensichtlich sind.
Der entscheidende Unterschied: ML vs. DL im Detail
Obwohl Deep Learning ein Teilbereich des Machine Learning ist, gibt es grundlegende Unterschiede in ihrer Funktionsweise, ihren Anforderungen und ihren Anwendungsbereichen. Das Verständnis dieser Unterschiede ist entscheidend, um die richtige Technologie für eine bestimmte Problemstellung auszuwählen.
1. Datenmenge und Rechenleistung
Der vielleicht praktisch relevanteste Unterschied liegt in den Anforderungen an Daten und Hardware. Traditionelle ML-Modelle können oft schon mit relativ kleinen Datenmengen gute Ergebnisse erzielen. Deine Leistungskurve flacht jedoch ab einem bestimmten Punkt ab; mehr Daten führen nicht zwangsläufig zu signifikant besseren Ergebnissen. Deep-Learning-Modelle hingegen sind datenhungrig. du benötigst riesige Datenmengen (oft Millionen von Datensätzen), um ihr volles Potenzial zu entfalten. Deine Leistung skaliert jedoch mit der Datenmenge: Je mehr Daten sie verarbeiten, desto besser werden sie.
Dieser Datenhunger geht Hand in Hand mit einem enormen Bedarf an Rechenleistung. Das Training komplexer neuronaler Netze erfordert spezialisierte Hardware, insbesondere leistungsstarke Grafikprozessoren (GPUs) oder sogar Tensor Processing Units (TPUs), die für die massiv parallelen Berechnungen in neuronalen Netzen optimiert sind. Das Training eines einzigen Deep-Learning-Modells kann Tage oder sogar Wochen dauern und erhebliche Kosten verursachen.
2. Feature Engineering
Wie bereits erwähnt, liegt ein weiterer Kernunterschied im Umgang mit den Merkmalen (Features) der Daten. Beim klassischen Machine Learning ist das "Feature Engineering" ein kritischer Schritt. Ein Datenwissenschaftler muss seine Expertise nutzen, um die relevanten Merkmale aus den Rohdaten zu extrahieren und für den Algorithmus aufzubereiten. Bei der Vorhersage von Kundenabwanderung könnten dies beispielsweise Merkmale wie die Nutzungsdauer, die Anzahl der Support-Anfragen oder das gebuchte Abonnement sein. Die Qualität dieser manuell ausgewählten Merkmale hat einen direkten Einfluss auf die Genauigkeit des Modells.
Deep Learning automatisiert diesen Schritt weitgehend. Durch die tiefen Schichten des neuronalen Netzes lernt das Modell selbstständig eine Hierarchie von Merkmalen. Es beginnt mit einfachen Mustern in den Rohdaten und kombiniert diese in den nachfolgenden Schichten zu immer komplexeren und abstrakteren Repräsentationen. Diese Fähigkeit zur automatischen Merkmalsextraktion macht Deep Learning besonders mächtig für unstrukturierte Daten wie Bilder oder Texte, bei denen manuelles Feature Engineering extrem schwierig oder unmöglich wäre.
3. Interpretierbarkeit (Black-Box-Problem)
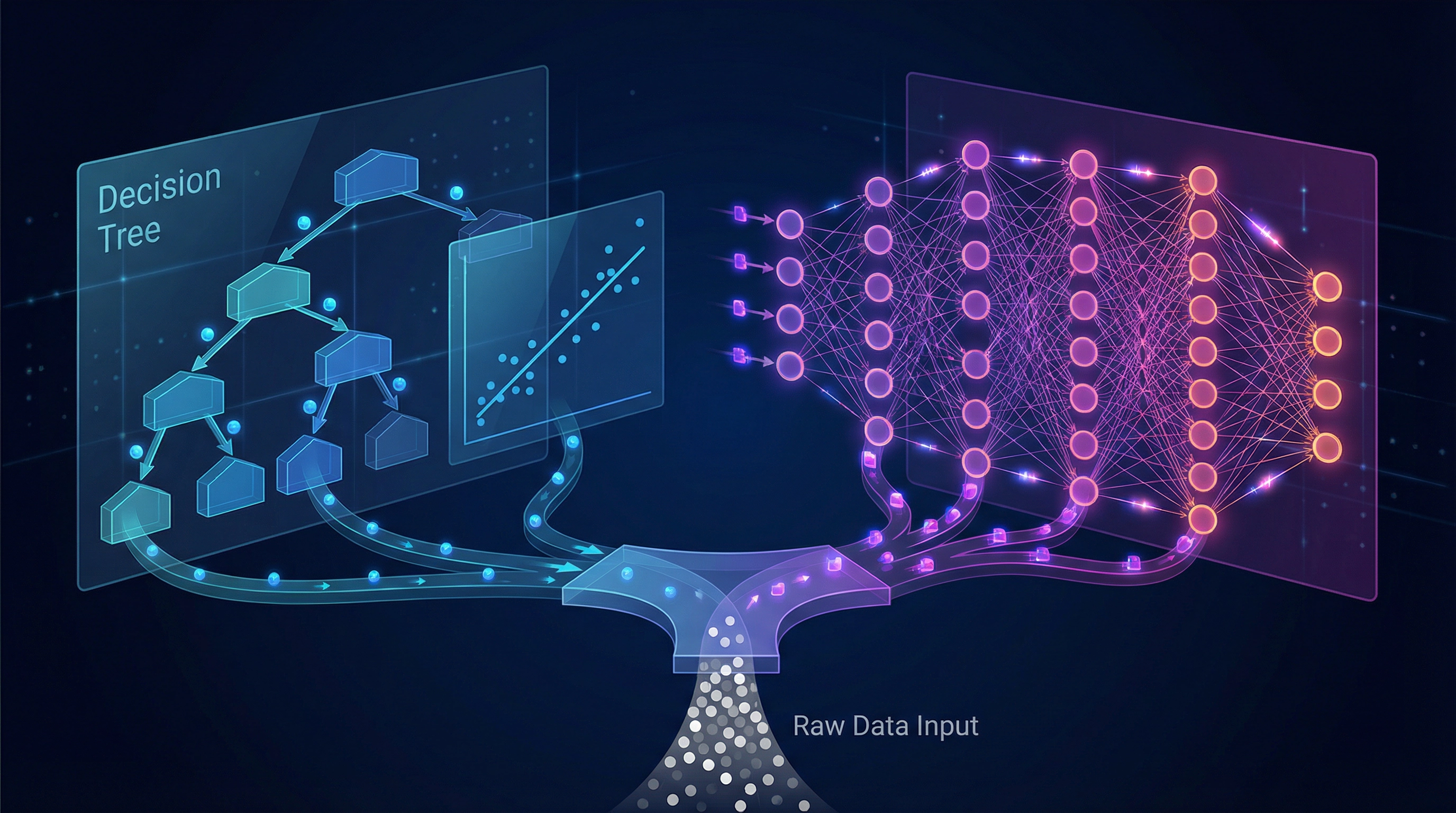
Ein Nachteil von Deep Learning ist die geringere Interpretierbarkeit. Während die Entscheidungswege vieler klassischer ML-Modelle (z.B. Entscheidungsbäume) relativ einfach nachzuvollziehen sind, agieren neuronale Netze oft als "Black Box". Aufgrund der Millionen von Parametern und der komplexen Wechselwirkungen zwischen den Neuronen ist es extrem schwierig zu verstehen, warum ein Modell eine bestimmte Entscheidung getroffen hat. Diese mangelnde Transparenz kann in regulierten Branchen wie dem Finanz- oder Gesundheitswesen problematisch sein, wo nachvollziehbare Entscheidungen gesetzlich vorgeschrieben sind. Die Forschung im Bereich "Explainable AI" (XAI) arbeitet intensiv an Lösungen für dieses Problem, aber es bleibt eine Herausforderung.
Neuronale Netze: Das Herzstück des Deep Learning
Um Deep Learning wirklich zu verstehen, müssen wir einen genaueren Blick auf seine Kernkomponente werfen: das künstliche neuronale Netz (KNN). Wie der Name schon andeutet, sind diese Netze von der Struktur und Funktionsweise des menschlichen Gehirns inspiriert. du bestehen aus einer großen Anzahl von miteinander verbundenen Verarbeitungseinheiten, den sogenannten künstlichen Neuronen oder Knoten.
Ein einzelnes Neuron ist eine relativ einfache mathematische Einheit. Es empfängt eine oder mehrere Eingaben, wendet eine Gewichtung auf jede Eingabe an (was die "Stärke" der Verbindung repräsentiert), summiert die gewichteten Eingaben und leitet das Ergebnis dann durch eine "Aktivierungsfunktion". Diese Funktion entscheidet, ob und wie stark das Neuron "feuert", also ein Signal an die nächste Schicht von Neuronen weitergibt. Dieser Prozess ähnelt der Art und Weise, wie biologische Neuronen durch elektrochemische Signale miteinander kommunizieren.
Die Architektur eines tiefen Netzes
- **Eingabeschicht (Input Layer):** Diese Schicht empfängt die Rohdaten. Für ein Bild könnte jedes Neuron einem Pixel entsprechen, für einen Text einem Wort oder Zeichen.
- **Versteckte Schichten (Hidden Layers):** Zwischen der Eingabe- und Ausgabeschicht liegen eine oder mehrere versteckte Schichten. Hier findet die eigentliche "Magie" statt. Jede Schicht empfängt die Ausgaben der vorherigen Schicht, verarbeitet sie und gibt sie an die nächste weiter. In diesen Schichten lernt das Netz, die hierarchischen Merkmale zu erkennen. Ein Netz wird als "tief" (deep) bezeichnet, wenn es mehrere versteckte Schriften besitzt.
- **Ausgabeschicht (Output Layer):** Diese letzte Schicht erzeugt das Endergebnis des Modells. Je nach Aufgabe kann dies eine einzelne Zahl (z.B. ein Preis), eine Wahrscheinlichkeitsverteilung über mehrere Klassen (z.B. bei der Bildklassifizierung "Hund", "Katze", "Pferd") oder eine Sequenz von Daten (z.B. bei der Textübersetzung) sein.
Der Prozess des "Lernens" besteht darin, die Gewichtungen der Verbindungen zwischen den Neuronen so anzupassen, dass der Fehler zwischen der Vorhersage des Modells und dem tatsächlichen Ergebnis minimiert wird. Dies geschieht durch einen Prozess namens "Backpropagation" (Fehlerrückführung) und Optimierungsalgorithmen wie dem Gradientenabstieg. Dieser Trainingsprozess erfordert, wie bereits erwähnt, enorme Datenmengen und Rechenleistung, ermöglicht es dem Netz aber, unglaublich komplexe Zusammenhänge zu modellieren.
Anwendungsfälle: Wo ML und DL in der Praxis glänzen
Die theoretischen Unterschiede werden am deutlichsten, wenn man sich die praktischen Anwendungsfälle ansieht. Während es Überschneidungen gibt, haben beide Technologien ihre spezifischen Stärken.
Typische Anwendungsfälle für Machine Learning:
- **Kundensegmentierung:** Ein Handelsunternehmen nutzt unüberwachtes Lernen, um seine Kunden anhand von Kaufhistorie, Demografie und Surfverhalten in verschiedene Gruppen einzuteilen. Dies ermöglicht personalisierte Marketingkampagnen und Produktempfehlungen.
- **Betrugserkennung:** Banken und Versicherungen setzen ML-Modelle ein, um Transaktionen in Echtzeit zu analysieren und verdächtige Muster zu erkennen, die auf Betrug hindeuten könnten. Hierfür werden gelabelte Daten aus vergangenen Betrugsfällen verwendet.
- **Vorhersagende Wartung (Predictive Maintenance):** In der Industrie analysieren ML-Algorithmen Sensordaten von Maschinen, um Ausfälle vorherzusagen, bevor sie auftreten. Dies ermöglicht eine proaktive Wartung und minimiert Ausfallzeiten.
- **E-Mail-Marketing-Optimierung:** Ein [KI-Agent für E-Mail](/ki-agent-fuer-email) kann mithilfe von ML vorhersagen, welche Betreffzeilen oder Versandzeiten die höchsten Öffnungsraten erzielen.
Typische Anwendungsfälle für Deep Learning:
- **Bild- und Objekterkennung:** Dies ist eine der Paradedisziplinen von Deep Learning. Selbstfahrende Autos nutzen DL, um andere Fahrzeuge, Fußgänger und Verkehrsschilder zu erkennen. In der Medizin werden DL-Modelle zur Analyse von Röntgenbildern oder MRT-Scans eingesetzt, um Tumore oder andere Anomalien mit hoher Präzision zu identifizieren.
- **Spracherkennung und -verarbeitung (NLP):** Digitale Assistenten wie Siri, Alexa oder der Google Assistant verwenden Deep Learning, um gesprochene Sprache zu verstehen und in Befehle umzusetzen. Auch die automatische Übersetzung von Texten, wie sie von Google Translate oder DeepL angeboten wird, basiert auf komplexen neuronalen Netzen. Ein [KI-Agent für Kundenservice](/ki-agent-fuer-kundenservice) kann so Kundenanfragen in natürlicher Sprache verstehen und beantworten.
- **Generative KI:** Modelle wie GPT-4 oder DALL-E, die in der Lage sind, menschenähnliche Texte zu schreiben oder realistische Bilder aus Textbeschreibungen zu erzeugen, sind ein Ergebnis fortschrittlichster Deep-Learning-Architekturen.
- **Personalisierte Empfehlungen:** Streaming-Dienste wie Netflix oder Spotify nutzen Deep Learning, um das Nutzerverhalten im Detail zu analysieren und hochgradig personalisierte Empfehlungen für Filme oder Musik auszuspielen.
Vergleichstabelle: Machine Learning vs. Deep Learning auf einen Blick
Die Zukunft von ML und DL: Trends und Prognosen
Die Entwicklung in den Bereichen Machine Learning und Deep Learning schreitet rasant voran. Einige Trends zeichnen sich bereits heute ab und werden die Zukunft der künstlichen Intelligenz maßgeblich prägen. Laut einer Studie von McKinsey wird erwartet, dass KI bis 2030 einen wirtschaftlichen Mehrwert von bis zu 13 Billionen US-Dollar generieren könnte, wobei ein Großteil dieses Wachstums auf fortschrittlichen ML- und DL-Anwendungen beruhen wird.
Ein wichtiger Trend ist die Demokratisierung der KI. Plattformen und Tools (wie unser [KI-Agent-Konfigurator](/ki-agent-konfigurator)) machen es auch Unternehmen ohne große Datenwissenschafts-Abteilungen zunehmend einfacher, ML- und DL-Modelle zu erstellen und zu nutzen. AutoML (Automatisiertes Maschinelles Lernen) geht noch einen Schritt weiter und automatisiert den gesamten Prozess von der Datenvorbereitung bis zur Modellerstellung.
Ein weiterer spannender Bereich ist das "TinyML", bei dem es darum geht, leistungsfähige Modelle auf sehr kleinen, energieeffizienten Geräten wie Mikrocontrollern laufen zu lassen. Dies eröffnet völlig neue Möglichkeiten für intelligente Geräte im Internet der Dinge (IoT), von sprachgesteuerten Haushaltsgeräten bis hin zu intelligenten Sensoren in der Landwirtschaft.
Im Bereich Deep Learning liegt ein starker Fokus auf der Entwicklung von noch größeren und leistungsfähigeren Modellen (Foundation Models) sowie auf der Verbesserung der Effizienz und der Reduzierung des "Black-Box"-Problems durch Explainable AI (XAI). Die Kombination verschiedener KI-Ansätze, wie die Verbindung von Deep Learning mit bestärkendem Lernen, verspricht ebenfalls weitere Durchbrüche, beispielsweise in der Robotik und bei autonomen Systemen.
Fazit: Die richtige Technologie für dein Unternehmen wählen
Machine Learning und Deep Learning sind beides extrem leistungsstarke Werkzeuge im Arsenal der künstlichen Intelligenz, aber du bist keine Universallösungen. Die Wahl der richtigen Technologie hängt entscheidend von der spezifischen Problemstellung, der Art und Menge der verfügbaren Daten sowie den vorhandenen Ressourcen ab. Klassisches Machine Learning ist oft die pragmatischere und kostengünstigere Wahl für Probleme mit strukturierten Daten und klaren Merkmalen. Deep Learning entfaltet seine wahre Stärke bei der Analyse riesiger Mengen unstrukturierter Daten und der Lösung hochkomplexer Aufgaben, die menschliche Wahrnehmungsfähigkeiten erfordern.
Für Unternehmen bedeutet dies, dass eine sorgfältige Analyse der eigenen Ziele und Gegebenheiten am Anfang jedes KI-Projekts stehen muss. Es geht nicht darum, die jeweils "fortschrittlichste" Technologie zu wählen, sondern die am besten geeignete. Oft ist eine Kombination aus verschiedenen Ansätzen der Schlüssel zum Erfolg.
Die Welt der KI entwickelt sich ständig weiter. Um wettbewerbsfähig zu bleiben, ist es für Unternehmen unerlässlich, die grundlegenden Konzepte zu verstehen und die Möglichkeiten zu erkennen, die sich daraus ergeben. Wir bei Prozessmeister sind darauf spezialisiert, Unternehmen wie deines auf diesem Weg zu begleiten. Wir helfen dir, die richtigen Anwendungsfälle zu identifizieren, die passende Technologie auszuwählen und maßgeschneiderte KI-Lösungen zu implementieren, die echten Mehrwert schaffen.
**Bist du bereit, das Potenzial von KI für dein Unternehmen zu nutzen? Vereinbare noch heute einen [kostenlosen Beratungstermin](/termin) mit unseren Experten und lass uns gemeinsam herausfinden, wie wir deine Prozesse optimieren können.**